Point-to-Point Communication Application - Random Walk
Author: Wes Kendall是时候使用 发送和接收教程 以及 MPI_Probe 和 MPI_Status 教程 中介绍的一些概念来研究具体的应用程序示例了。
本文应用程序模拟了一个被称之为“随机游走”的过程。
注意 - 该站点的所有代码都位于 GitHub。本文的代码位于此 tutorials/point-to-point-communication-application-random-walk/code 目录下。
随机游走的基本问题定义如下: 给定 Min,Max 和随机游走器 W,让游走器 W 向右以任意长度的 S 随机移动。 如果该过程越过边界,它就会绕回。 W 一次只能左右移动一个单位。

尽管程序本身是非常基础的,但是并行化的随机游走可以模拟各种并行程序的行为。 具体内容以后再说。 现在,让我们概述一下如何并行化随机游走问题。
随机游走问题的并行化
在许多并行程序的应用中,首要任务是在各个进程之间划分域。 随机行走问题的一维域大小为 Max - Min + 1(因为游走器包含 Max 和 Min)。 假设游走器只能采取整数大小的步长,我们可以轻松地将域在每个进程中划分为大小近乎相等的块。 例如,如果 Min 为 0,Max 为 20,并且我们有四个进程,则将像这样拆分域。
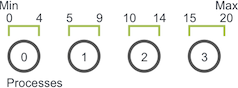
前三个进程拥有域的五个单元,而最后一个进程则拥有最后五个单元并且再加上一个剩余的单元。 一旦对域进行了分区,应用程序将初始化游走器。 如前所述,游走器将以步长 S 进行总步数随机的游走。 例如,如果游走器在进程 0(使用先前的分解域)上进行了移动总数为 6 的游走,则游走器的执行将如下所示:
-
游走器的步行长度开始增加。但是,当它的值达到 4 时,它已到达进程 0 的边界。因此,进程 0 必须与进程 1 交流游走器的信息。
-
进程 1 接收游走器,并继续移动,直到达到移动总数 6。然后,游走器可以继续进行新的随机移动。
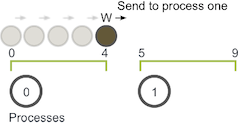
在此示例中,W 仅需从进程 0 到进程 1 进行一次通信。 但是,如果 W 必须移动更长的距离,则可能需要沿其通过域的路径将其传递给更多的进程。
使用 MPI_Send 和 MPI_Recv 组织代码
可以使用 MPI_Send 和 MPI_Recv 对组织代码。
在开始查看代码之前,让我们建立程序的一些初步特征和功能:
- 明确每个进程在域中的部分。
- 每个进程初始化 N 个 walker,所有这些 walker 都从其局部域的第一个值开始。
- 每个 walker 都有两个相关的整数值:当前位置和剩余步数。
- Walkers 开始遍历该域,并传递到其他进程,直到完成所有移动。
- 当所有 walker 完成时,该进程终止。
让我们从编写用于分解域的代码开始。
该函数将考虑域的总大小,并为 MPI 进程找到合适的子域。
它还会将域的其余部分交给最终的进程。
为了简单起见,我会调用 MPI_Abort 处理发现的任何错误。
名为 decompose_domain 的函数如下所示:
void decompose_domain(int domain_size, int world_rank,
int world_size, int* subdomain_start,
int* subdomain_size) {
if (world_size > domain_size) {
// Don't worry about this special case. Assume the domain
// size is greater than the world size.
MPI_Abort(MPI_COMM_WORLD, 1);
}
*subdomain_start = domain_size / world_size * world_rank;
*subdomain_size = domain_size / world_size;
if (world_rank == world_size - 1) {
// Give remainder to last process
*subdomain_size += domain_size % world_size;
}
}
如您所见,该函数将域分成偶数个块,并考虑了存在余数的情况。 该函数返回一个子域开始和一个子域大小。
接下来,我们需要创建一个初始化 walkers 的函数。 我们首先定义一个如下所示的 walker 结构:
typedef struct {
int location;
int num_steps_left_in_walk;
} Walker;
我们的初始化函数为 initialize_walkers,它采用子域边界,并将 walker 添加到 incoming_walkers vector 中(顺便说一下,该程序采用 C++)。
void initialize_walkers(int num_walkers_per_proc, int max_walk_size,
int subdomain_start, int subdomain_size,
vector<Walker>* incoming_walkers) {
Walker walker;
for (int i = 0; i < num_walkers_per_proc; i++) {
// Initialize walkers in the middle of the subdomain
walker.location = subdomain_start;
walker.num_steps_left_in_walk =
(rand() / (float)RAND_MAX) * max_walk_size;
incoming_walkers->push_back(walker);
}
}
初始化之后,就该使 walkers 前进了。
让我们从一个移动功能开始。
此功能负责使 walkers 前进,直到完成移动为止。
如果超出局部域范围,则将其添加到 outgoing_walkers vector 中。
void walk(Walker* walker, int subdomain_start, int subdomain_size,
int domain_size, vector<Walker>* outgoing_walkers) {
while (walker->num_steps_left_in_walk > 0) {
if (walker->location == subdomain_start + subdomain_size) {
// Take care of the case when the walker is at the end
// of the domain by wrapping it around to the beginning
if (walker->location == domain_size) {
walker->location = 0;
}
outgoing_walkers->push_back(*walker);
break;
} else {
walker->num_steps_left_in_walk--;
walker->location++;
}
}
}
现在,我们已经建立了初始化函数(用于填充传入的 walker 列表)和移动函数(用于填充传出的 walker 列表),我们仅再需要两个函数:发送待传出的 walker 的函数和接收待传入的 walker 的函数。 发送功能如下所示:
void send_outgoing_walkers(vector<Walker>* outgoing_walkers,
int world_rank, int world_size) {
// Send the data as an array of MPI_BYTEs to the next process.
// The last process sends to process zero.
MPI_Send((void*)outgoing_walkers->data(),
outgoing_walkers->size() * sizeof(Walker), MPI_BYTE,
(world_rank + 1) % world_size, 0, MPI_COMM_WORLD);
// Clear the outgoing walkers
outgoing_walkers->clear();
}
接收传入的 walkers 的函数应该使用 MPI_Probe,因为它事先不知道将接收多少 walkers。
看起来是这样的:
void receive_incoming_walkers(vector<Walker>* incoming_walkers,
int world_rank, int world_size) {
MPI_Status status;
// Receive from the process before you. If you are process zero,
// receive from the last process
int incoming_rank =
(world_rank == 0) ? world_size - 1 : world_rank - 1;
MPI_Probe(incoming_rank, 0, MPI_COMM_WORLD, &status);
// Resize your incoming walker buffer based on how much data is
// being received
int incoming_walkers_size;
MPI_Get_count(&status, MPI_BYTE, &incoming_walkers_size);
incoming_walkers->resize(
incoming_walkers_size / sizeof(Walker));
MPI_Recv((void*)incoming_walkers->data(), incoming_walkers_size,
MPI_BYTE, incoming_rank, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
}
现在我们已经建立了程序的主要功能。 我们必须将所有这些功能集成在一起,如下所示:
- 初始化 walkers.
- 使用
walk函数使 walkers 前进。 - 发出
outgoing_walkers向量中的所有的 walkers。 - 将新接收的 walkers 放入
incoming_walkers向量中。 - 重复步骤 2 到 4,直到所有 walkers 完成。
下面是完成此程序的第一次尝试。 此刻,我们不必担心如何确定所有 walkers 完成的时间。 但在查看代码之前,我必须警告您-该代码不正确! 知晓这个问题以后,让我们看一下代码,希望您能发现它可能有什么问题。
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start, subdomain_size,
&incoming_walkers);
while (!all_walkers_finished) { // Determine walker completion later
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
}
一切看起来都很正常,但是函数调用的顺序引入了一种非常可能的情形 - 死锁。
死锁及预防
根据 Wikipedia 的说法,死锁 是指两个或多个进程各自在等待另一个进程释放资源,或者两个或多个进程在循环链中等待资源的特定条件。 代码将导致 MPI_Send 调用的循环链。
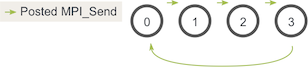
值得注意的是,上面的代码在大多数情况下实际上不会“死锁”。
尽管 MPI_Send 是一个阻塞调用,但是 MPI 规范 表明 MPI_Send 会一直阻塞,直到可以回收发送缓冲区为止。
这意味着当网络可以缓冲消息时,MPI_Send 将返回。
如果发送最终无法被网络缓冲,它们将一直阻塞直到发布匹配的接收。
在我们的例子中,有足够多的小发送和频繁匹配的接收而不必担心死锁,但是,永远不该假定有足够大的网络缓冲区。
由于在本文中我们仅关注 MPI_Send 和 MPI_Recv,因此避免可能发生的发送和接收死锁的最佳方法是对消息进行排序,以使发送将具有匹配的接收,反之亦然。
一种简单的方法是更改循环,以使偶数编号的进程在接收 walkers 之前发送传出的 walkers,而奇数编号的进程则相反。
在执行的两个阶段,发送和接收现在看起来像这样:
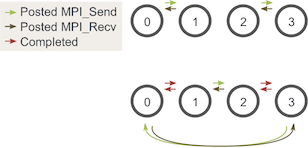
注意 - 使用一个进程执行此操作仍可能会死锁。为了避免这种情况,仅在使用一个进程时不要执行发送和接收。
您可能会问,这仍然适用于奇数个进程吗? 我们可以通过三个过程再次查看相似的图表:
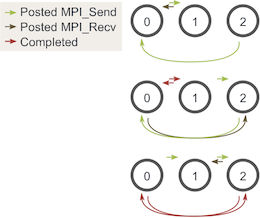
如您所见,在所有三个阶段中,至少有一个发布的 MPI_Send 与发布的 MPI_Recv 匹配,因此我们不必担心死锁的发生。
Determining completion of all walkers
现在是程序的最后一步 - 确定每个 walker 何时结束。 由于 walkers 可以随机行走,因此它们可以在任何一个进程中结束它们的旅程。 因此,如果没有某种额外的通信,所有进程都很难知道 walkers 何时全部结束。 一种可能的解决方案是让进程零跟踪所有已完成的 walker,然后告诉其他所有进程何时终止。 但是,这样的解决方案非常麻烦,因为每个进程都必须向进程 0 报告所有完成的 walker,然后还要处理不同类型的传入消息。
在本文中,我们让这件事情稍微简单一点。 由于我们知道任意一个 walker 可以行进的最大距离和每对发送和接收对它可以行进的最小总大小(子域大小),因此我们可以计算出终止之前每个进程应该执行的发送和接收量。 在我们避免死锁的策略中考虑这一特征,该程序的最后主要部分如下所示:
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start, subdomain_size,
&incoming_walkers);
// Determine the maximum amount of sends and receives needed to
// complete all walkers
int maximum_sends_recvs =
max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) {
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
// Send and receive if you are even and vice versa for odd
if (world_rank % 2 == 0) {
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
} else {
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
}
}
Running the application
代码可在 此处查看. 与其他教程相反,此处代码使用 C++。 在 安装 MPICH2 时,还安装了 C++ MPI 编译器(除非您另有明确配置)。 如果将 MPICH2 安装在本地目录中,请确保已将 MPICXX 环境变量设置为指向正确的 mpicxx 编译器,以便使用我的 makefile。
在我的代码中,我设置了运行脚本来提供运行的默认值:域大小为 100,最大步行大小为 500,每个进程的步行者数量为 20。 如果您从 repo 的 tutorials 目录运行 random_walk 程序,它应该产生 5 个进程,并产生与下方类似的输出。
>>> cd tutorials
>>> ./run.py random_walk
mpirun -n 5 ./random_walk 100 500 20
Process 2 initiated 20 walkers in subdomain 40 - 59
Process 2 sending 18 outgoing walkers to process 3
Process 3 initiated 20 walkers in subdomain 60 - 79
Process 3 sending 20 outgoing walkers to process 4
Process 3 received 18 incoming walkers
Process 3 sending 18 outgoing walkers to process 4
Process 4 initiated 20 walkers in subdomain 80 - 99
Process 4 sending 18 outgoing walkers to process 0
Process 0 initiated 20 walkers in subdomain 0 - 19
Process 0 sending 17 outgoing walkers to process 1
Process 0 received 18 incoming walkers
Process 0 sending 16 outgoing walkers to process 1
Process 0 received 20 incoming walkers
输出将一直持续到各个进程完成所有 walkers 的发送和接收。
下一步是什么?
接下来,我们将开始学习 MPI 中的集体通信。 我们将从 MPI Broadcast 开始,对于所有教程,请转到 MPI tutorials.
另外,在一开始,我告诉您本文中的程序的概念适用于许多并行程序。 我不想让您垂涎三尺,因此,我在下面提供了一些其他阅读材料,供那些希望了解更多信息的人使用。 请享用 :-)
附加阅读 - 随机游走及其与并行粒子跟踪的相似性
我们刚刚实现的随机游走问题虽然看似微不足道,但实际上可以构成模拟多种并行应用程序的基础。 科学领域中的某些并行应用程序需要多种类型的随机发送和接收。 一种示例应用是并行粒子跟踪。

并行粒子跟踪是用于可视化流场的主要方法之一。 将粒子插入流场,然后使用数值积分技术(例如 Runge-Kutta)沿流线跟踪。 然后可以呈现跟踪的路径以用于可视化目的。 一个示例渲染是左上方的龙卷风图像。
执行有效的并行粒子跟踪可能非常困难。 这样做的主要原因是,只有在积分的每个增量步骤之后才能确定粒子行进的方向。 因此,线程很难协调和平衡所有通信和计算。 为了更好地理解这一点,让我们看一下粒子跟踪的典型并行化。
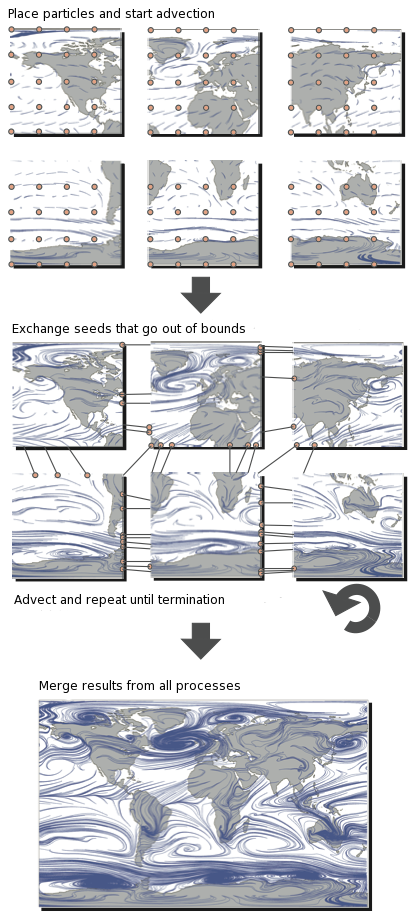
在此插图中,我们看到该域分为六个过程。 然后将粒子(有时称为种子)放置在子域中(类似于我们将 walkers 放置在子域中的方式),然后开始跟踪它们。 当粒子超出范围时,必须与具有适当子域的进程进行交换。 重复此过程,直到粒子离开整个域或达到最大迹线长度为止。
可以使用 MPI_Send,MPI_Recv 和 MPI_Probe 来解决并行粒子跟踪问题,其方式与我们刚刚实现的应用程序类似。
当然,还有许多更复杂的 MPI 例程可以更有效地完成这样的工作。
我们将在接下来的教程中讨论这些问题:-)
我只是希望您现在至少可以看到一个例子来说明随机游走问题与其他并行应用程序有何相似之处!